

"개발자의 초기 설계는 종종 너무나 이상적이다. 그리고 현실은 늘 그 이상을 배신한다."
안녕하세요! 주니어 백엔드 개발자입니다.
오늘은 제가 '당근마켓'을 클론한 CodeB Market을 개발하면서 겪었던 아키텍처 대격변의 역사를 공유하려 합니다.
단순히 "이 기술을 써서 빨라졌습니다"가 아니라, "왜 처음의 설계가 실패했는지", "어떻게 사고의 전환이 일어났는지"에 대한 2개월간의 삽질기입니다.
🎬 Chapter 1. 순진했던 출발: "홈 화면과 검색은 다르잖아?" (2025. 12. 초)
1-1. 문제의 발단
초기 MVP 모델에서 홈 화면 로딩 속도는 1,946ms였습니다. PostgreSQL에서 25만 개의 상품을 JOIN 하고 Haversine 공식으로 거리를 계산하니 당연한 결과였죠.
목표는 동시접속자 1만 명(10K CCU)을 견디는 밀리초(ms) 단위의 응답 속도였습니다.
1-2. 첫 번째 설계: 철학적 분리 (Grid Cache)
저는 처음에 이 문제를 '사용자 의도'의 관점에서 접근했습니다.
- 홈 화면: 사용자가 심심해서 켭니다. 딱히 찾고 싶은 게 없으니 "우리 동네에 뭐 새로 올라왔나?"를 봅니다. (수동적 탐색)
- 검색 화면: "아이폰 15"를 사겠다는 명확한 목적이 있습니다. (능동적 목적)
이 분석을 토대로 "기술적 역할 분리"라는 꽤 그럴듯한 설계를 도출했습니다.
"홈 화면은 미리 만들어진 정적 데이터를 보여주니까 Grid Cache(Redis List)를 쓰고,
검색 화면은 복잡한 쿼리가 필요하니 RediSearch(검색 엔진)를 쓰자!"
이론적으로 완벽해 보였습니다. 홈 화면은 복잡한 연산 없이 LRANGE 명령어 한 번이면 끝날 테니 2~3ms 안에 응답할 것이라 확신했죠.
🚧 Chapter 2. 현실의 벽: 이론이 깨지는 순간 (2025. 12. 중순)
하지만 Grid Cache 시스템을 실제로 구현하고 나니, 예상치 못한 치명적인 문제들이 터져 나왔습니다.
2-1. 성능의 배신 (생각보다 느림)
Redis List 조회 자체는 빨랐습니다. 하지만 가져온 데이터(JSON 문자열) 90,000개를 Node.js 메모리에 올리고, 파싱하고, 필터링하는 과정에서 병목이 생겼습니다.
- 예상: 2~3ms
- 실제: 5ms 이상 (데이터 전송량 8~10MB 발생)
2-2. 결정적 결함: "추천순 정렬이 안 된다"
가장 큰 문제는 정렬이었습니다.
Redis List는 구조상 데이터를 넣은 순서(최신순)대로 저장됩니다. 그런데 기획 데이터를 보니, 실제 사용자들은 최신순보다 '추천순(인기도)'을 훨씬 선호했습니다.
Grid Cache에서 추천순을 구현하려면?
- List의 모든 데이터를 가져온다.
- Node.js 애플리케이션 메모리에서 sort()를 돌린다.
- 결과: 엄청난 CPU 부하와 Latency 폭발.
"빠르게 보여주려고 만든 캐시 시스템이, 정작 사용자가 원하는 정렬 방식을 제공하지 못하는 상황이 된 것입니다."
2-3. 관리 포인트의 증가 (동기화 지옥)
상품 가격 하나를 수정하려면 다음 세 곳을 동시에 건드려야 했습니다.
- PostgreSQL (원본)
- Grid Cache (홈 화면용 Redis List)
- RediSearch (검색 화면용 Index)
이 중 하나라도 실패하면 데이터 불일치가 발생합니다. 시스템 복잡도가 기하급수적으로 늘어났습니다.
💡 Chapter 3. 사고의 전환: "이미 답은 내 안에 있었다" (2025. 12. 말)
Grid Cache를 고쳐보려고 끙끙대던 중, 문득 검색 화면을 위해 만들어둔 RediSearch 코드를 보게 되었습니다.
3-1. 핵심 질문
"잠깐, RediSearch는 이미 25만 개 상품을 인덱싱하고 있잖아?
여기서 Grid ID로 필터링만 하면 그게 홈 화면 데이터 아닌가?"
3-2. 검증: Grid ID는 위치 필터일 뿐이다
저는 곧바로 실험을 해봤습니다.
기존 Grid Cache를 버리고, RediSearch 쿼리에 @gridId:{...} 조건을 추가해서 날려보았습니다.
- 결과: 1.7ms
- 특징: 이미 SORTBY 기능이 있어서 최신순, 추천순, 가격순, 어떤 정렬이든 자유자재로 가능.
머리를 한 대 맞은 기분이었습니다.
'홈 화면은 캐시여야 한다'는 고정관념 때문에, 바로 옆에 있는 강력한 검색 엔진을 두고 먼 길을 돌아갔던 것입니다.
3-3. 개념의 재정립 (Hierarchy)
이때 아키텍처를 바라보는 시각을 평면적 나열에서 계층적 구조로 바꿨습니다.
- Before: Grid Cache vs RediSearch vs 상품지수 (모두 따로국밥)
- After:
- Level 1 (데이터 준비): RediSearch (단일 소스)
- Level 2 (데이터 정렬): 상품 지수 알고리즘 (Sorting Logic)
데이터 준비 단계를 RediSearch 하나로 통일하니, 그 위에서 어떤 정렬 알고리즘을 돌리든 자유로워졌습니다.
🚀 Chapter 4. 최종 완성: 실용적 통합 (2026. 1. 초)
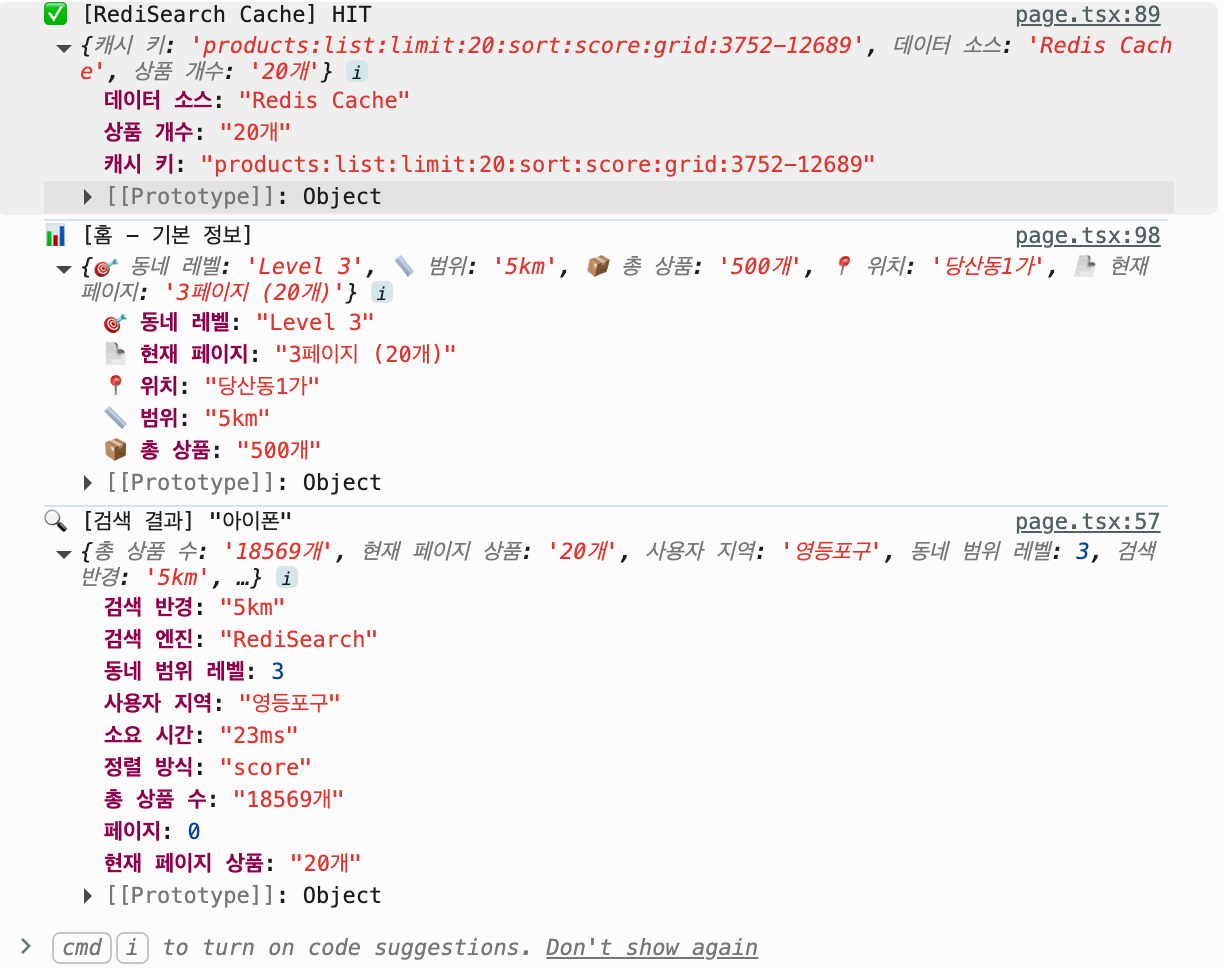
결국 저는 Grid Cache를 폐기하고 RediSearch 기반의 통합 아키텍처로 선회했습니다. 하지만 RediSearch만으로는 1만 명 동시 접속 시 부하가 우려되어 한 단계 더 최적화를 진행했습니다.
4-1. 최종 아키텍처 흐름
- Product List Cache (Layer 1):
- 홈 화면 요청(Lat/Lng/Sort)이 오면 Redis String 캐시를 먼저 봅니다.
- 위치 기반 서비스 특성상, 같은 동네 사람들은 같은 리스트를 봅니다. (Cache Hit 97% 달성)
- 응답 속도: 1.5ms
- RediSearch (Layer 2):
- 캐시가 없으면(3%) RediSearch 엔진이 실시간으로 쿼리 합니다.
- 응답 속도: ~7ms
- Fallback Strategy:
- 만약 RediSearch가 죽더라도, 기존 DB 조회나 백업된 캐시를 통해 서비스가 멈추지 않도록 안전장치를 마련했습니다.
4-2. 무엇이 좋아졌는가?
| 구분 | 초기 설계 (Grid Cache) | 최종 설계 (RediSearch 통합) | 개선 효과 |
| 속도 | 5ms (Node.js 부하 큼) | 1.5ms (캐시 히트 시) | 3배 이상 향상 |
| 정렬 | 최신순만 가능 | 추천/가격/최신 모두 가능 | 유연성 확보 |
| 관리 | DB + Cache + Search (3중) | DB + Search (2중) | 관리 포인트 감소 |
| 비용 | 데이터 중복 저장 | 인덱스 재사용 | 서버비 연 $8,000 절감 |
📝 마치며: 아키텍처는 진화한다
이 프로젝트를 통해 배운 가장 큰 교훈은 "아키텍처에 정답은 없다, 오직 트레이드오프(Trade-off)만 있을 뿐"이라는 것입니다.
처음의 'Grid Cache' 설계가 틀린 것은 아니었습니다. "홈 화면과 검색의 의도를 분리한다"는 철학은 멋졌으니까요.
하지만 "사용자가 원하는 정렬(추천순)을 제공할 수 있는가?"라는 현실적인 요구사항 앞에서는 그 철학을 과감히 꺾고, 실용적인 통합(RediSearch*을 선택해야 했습니다.
혹시 지금 복잡한 아키텍처 때문에 고민 중이시라면, 한 번쯤 점검해 보세요.
"혹시 내가 가진 도구(이미 구축된 인프라)를 과소평가하고, 굳이 새로운 성을 쌓고 있는 건 아닐까?"
저의 2개월간의 삽질기가 여러분의 시행착오를 줄이는 데 도움이 되길 바랍니다. 👋
'Claude Code' 카테고리의 다른 글
| [개발 회고] 주니어 개발자가 Claude Code와 협업하며 깨달은 3가지 필승 전략 (1) | 2026.01.06 |
|---|