
https://github.com/scofield7419/EmpathyEar
GitHub - scofield7419/EmpathyEar: Multimodal Empathetic Chatbot
Multimodal Empathetic Chatbot. Contribute to scofield7419/EmpathyEar development by creating an account on GitHub.
github.com
https://arxiv.org/abs/2406.15177
EmpathyEar: An Open-source Avatar Multimodal Empathetic Chatbot
This paper introduces EmpathyEar, a pioneering open-source, avatar-based multimodal empathetic chatbot, to fill the gap in traditional text-only empathetic response generation (ERG) systems. Leveraging the advancements of a large language model, combined w
arxiv.org
아키텍쳐 및 작업흐름 요약
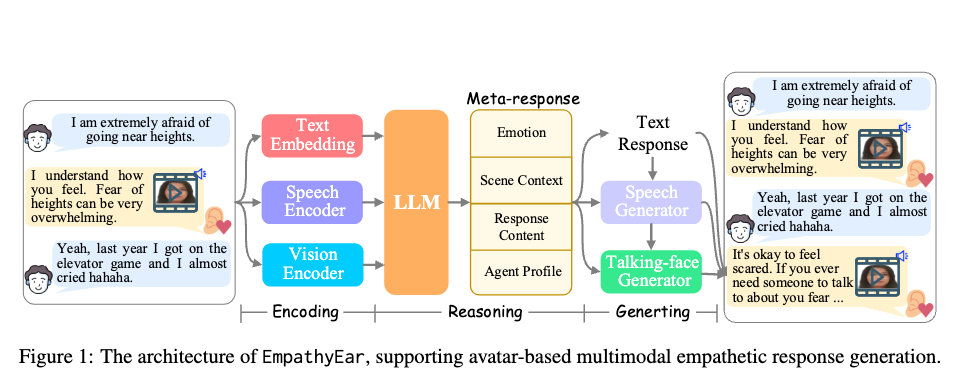
EmpathyEar는 다중 모달 LLM입니다.
전체 시스템은 인코딩, 추론, 생성의 세 가지 블록으로 나눌 수 있습니다.
▶1단계: 사용자 질문 전달/API 호출
우리 시스템은 웹사이트 인터페이스 또는 사전에 정의된 API를 통해 사용자 입력을 수락합니다. 텍스트 입력, 음성(스피치) 입력, 또는 사용자가 말하는 영상 입력을 지원합니다.
▶2단계: 사용자 및 맥락(다중 모달) 입력 인코딩
사용자가 입력한 콘텐츠는 대화의 역사적 맥락과 함께 인코딩됩니다. 사용자의 입력이 텍스트만 포함된 경우, 그것은 직접 LLM(대형 언어 모델)으로 전달됩니다. 그러나 다중 모달 정보(음성 또는 영상)가 포함된 경우, 먼저 다중 모달 인코더를 거친 후 LLM으로 입력됩니다.
- 다중 모달 인코더(multimodal encoder)란?
- Text Embedding
- 사용자가 입력한 텍스트 데이터를 처리하고, 이를 모델이 이해할 수 있는 임베딩(embedding) 형태로 변환합니다.
- 텍스트 입력이 단독으로 주어졌을 경우, 바로 LLM으로 전달됩니다.
- Speech Encoder
- 사용자가 음성으로 입력한 데이터를 처리하여, 음성 신호에서 중요한 특징(예: 음성의 내용, 감정, 억양 등)을 추출합니다.
- 음성 데이터를 텍스트로 변환하거나, 음성 자체의 특성을 분석하여 LLM으로 전달합니다.
- Vision Encoder
- 사용자가 영상(예: 얼굴 표정, 제스처 등)을 입력한 경우, 이를 처리하여 영상에서 중요한 특징(예: 시각적 감정 표현, 얼굴 움직임 등)을 추출합니다.
- 이러한 시각적 정보를 LLM에 전달해 응답 생성에 반영합니다.
- Text Embedding
- 텍스트, 음성, 영상 등 다양한 입력 데이터를 처리하기 위한 모듈로 구성되며, 그림에서 언급된 Text Embedding, Speech Encoder, Vision Encoder가 각각 텍스트, 음성, 영상 입력을 처리하는 역할
- 다중 모달 특징을 동시에 인코딩하기 위해 사용된 것: ImageBind
- 우리는 이러한 다중 모달 특징을 동시에 인코딩하기 위해 ImageBind(Girdhar et al., 2023)를 활용하는 통합 접근 방식을 고려했습니다. ImageBind는 광범위한 **교차 모달 특징 정렬(cross-modal feature alignment)**을 거쳤으며, 다양한 모달리티 간 특징을 효율적으로 정렬할 수 있습니다. 그런 다음, **선형 투영층(linear projection layer)**을 통해 다중 모달 정보를 LLM으로 전달합니다.
- 파인튜닝1. 인코더 - LLM 정렬학습
- ‘오디오-텍스트’ 및 ‘비디오-텍스트’ 쌍에 대한 정렬학습을 수행합니다. 오디오와 비디오를 입력한 후, LLM이 해당하는 캡션을 출력하도록 설계합니다.
- ‘감정인식 기반 다중모달 정렬’을 수행하여 ImageBind & LLM이 음성과 비디오에서 감정특징을 인식하는 능력을 강화합니다. 이를 위해, 관련 데이터셋(예: EGG (Soleymani et al., 2015))을 사용하여 음성 기반(Sailunaz et al., 2018) 및 비전 기반(Jaiswal et al., 2020) 감정 인식 작업을 수행합니다.
- 시스템의 프론트엔드 모듈인 ImageBind를 LLM과 정렬하여, LLM이 다중 모달 정보를 이해할 수 있도록 합니다. 정렬은 두 가지 측면에서 고려됩니다
▶3단계: LLM을 사용한 메타 응답 생성
LLM은 입력된 콘텐츠를 완전히 이해하고, 이에 따라 결정합니다. 이 과정에서 감정 이해, 장면 이해, 사용자에게 반환될 텍스트 응답, 그리고 에이전트 프로필의 위치 설정을 포함한 메타 응답을 출력합니다.
- '메타 응답'이란?
- '메타 응답'이라는 용어는 단순한 텍스트 응답 이상의 정보를 포함하는, 시스템이 생성하는 고차원적인 응답을 의미 즉, 메타 응답은 단순히 사용자 질문에 대한 답변만 제공하는 것이 아니라, 시스템이 응답을 생성하기 위해 고려한 다양한 요소와 정보를 통합한 결과물을 말합니다.
- 사용된 백본(Backbone) LLM: Chat-GLM3
Chat-GLM3는 중국 기반의 Tsinghua University 와 Zhipu AI에서 개발한 모델로, 중국어와 영어를 포함한 다국어 환경에서 최적화된 GLM(General Language Model) 시리즈의 최신 버전입니다. 특히, 중국어 자연어 처리(NLP)에 강점을 가지고 있으며, 아시아 언어에 특화된 데이터셋으로 학습된 점이 특징입니다 - 다중 모달 입력을 받으면, LLM은 사용자의 **의미적 의도(semantic intentions)**와 **감정 상태(emotional state)**를 이해하여, 이후 콘텐츠 생성을 위한 모든 필수 정보를 포함한 **메타 응답(meta-response)**을 생성합니다.
- 이는 ChatGLM이 **Vicuna(Chiang et al., 2023)**나 **LLaMA(Touvron et al., 2023)**와 같은 다른 모델에 비해 뛰어난 텍스트 이해 및 대화 능력을 제공하기 때문입니다.
- 선형적으로 연결된 추론(linearly chained reasoning)우리는 LLM이 메타 응답의 네 가지 부분을 순차적으로 출력하도록 추가 프롬프트를 추가해 이를 안내합니다:
“1) 감정 → 2) 장면 맥락 → 3) 응답 내용 → 4) 에이전트 프로필을 단계별로 생각해 주세요.” - 파인튜닝2. 메타 응답 지침 튜닝
- 32가지 감정 레이블 유형(명시적 감정 유형과 암시적 감정 유형 모두 포함), 200개 이상의 실제 시나리오
- 우리는 OpenAI GPT-4(OpenAI, 2022a)를 활용하여 위에서 정의된 메타 응답 형식에 따라 풍부한 데이터를 생성합니다. 우리는 GPT-4가 CoT(Chain-of-Thought) 추론 형식을 완전히 준수하도록 프롬프트를 제공하여, LLM이 이 과정을 시뮬레이션하도록 합니다.


▶4단계: 참조 음성 검색
메타 응답에서 지정된 감정 레이블, 성별 및 음성 톤(timbre)을 기반으로 데이터베이스에서 참조 음성을 검색합니다.
▶5단계: 감정 인식 음성 생성
텍스트 응답과 참조 음성을 음성 생성기에 입력하여, 감정을 반영한 목표 음성을 생성합니다.
- 사용된 음성 생성기: StyleTTS2
- StyleTTS2는 주어진 텍스트, 감정 레이블, 그리고 참조 음성(예: 음색 및 성별 특성)을 기반으로 음성을 생성합니다.
▶ 6단계: 참조 얼굴 이미지 검색
메타 응답에서 결정된 프로필의 연령 및 성별 정보를 사용해 데이터베이스에서 참조 얼굴 이미지를 검색합니다.
▶ 7단계: 감정 인식 말하는 얼굴 아바타 영상 생성
생성된 감정을 반영한 음성과 참조 얼굴 이미지를 말하는 얼굴 생성기에 입력하여, 목표 감정을 반영한 말하는 얼굴 아바타 영상을 생성합니다.
- 사용된 얼굴 아바타 영상 생성기: EAT
- EAT는 주어진 음성, 감정 레이블, 그리고 디지털 인간의 얼굴 특징을 결정하는 참조 이미지를 조건으로 하여 해당 영상을 생성합니다.
- 디지털 아바타 캐릭터의 사전 설정 개요표 1: 우리 시스템에서 디지털 아바타 캐릭터의 사전 설정 개요
- 감정 레이블, 성별, 나이, 장면(scene), 음색(timbre) 및 톤(tone)을 포함
- 명시적(explicit) 및 암시적(implicit) 유형을 모두 아우르는 32가지의 일반적인 감정 레이블을 제공
- 인간의 나이는 신체적 외형 변화의 주요 단계를 기준으로 6단계
- 우리 시스템은 200개 이상의 실제 시나리오를 지원하며, 풍부한 음색과 톤을 가진 음성을 생성
- 파인튜닝3. 감정 인식 강화 학습
구체적으로, 음성 생성기와 얼굴 생성기를 각각 감정 음성 및 비디오 데이터셋인 **ESD (Zhou et al., 2022)**와 **MEAD (Wang et al., 2020)**에 대해 미세 조정(fine-tuning)합니다. 또한, ESD와 MEAD 데이터셋을 우리의 요구에 맞게 약간 수정합니다. - 예를 들어, 비디오 음성에서 텍스트를 인식한 후 이를 기반으로 음성 텍스트를 준비합니다.
- 백엔드 음성 생성기와 얼굴 생성기(talking-face generator)의 감정 인식 능력을 강화하기 위해, 기존의 관련 다중 모달 데이터를 활용하여 이 모듈들에 대해 추가 학습을 진행합니다.

▶8단계: 아바타 기반 다중 모달 공감 응답 반환
시스템은 이번 턴의 전체 출력 콘텐츠로 텍스트 응답, 음성, 말하는 얼굴 아바타 영상을 요약하여 사용자에게 반환합니다.
- 비디오 데모: https://youtu.be/gGn9oYftwbY
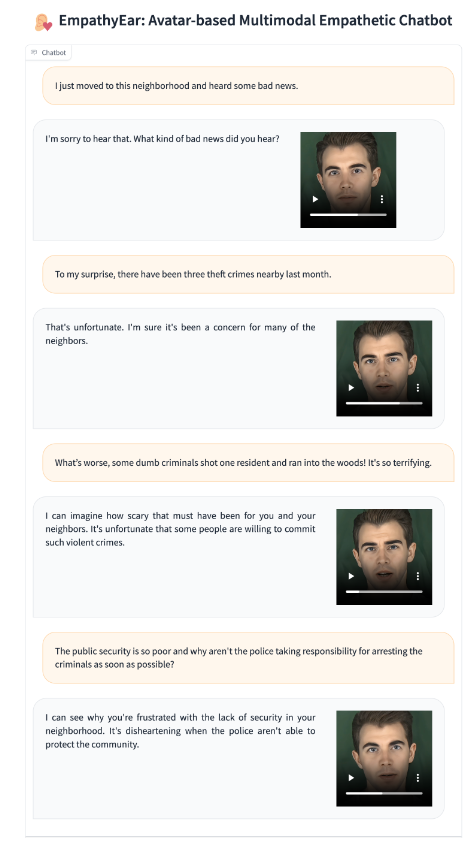
그림 3과 4에서는 두 가지 시나리오(노인 동반자 및 심리 상담)에서 시스템이 사용자와 상호작용하는 모습을 보여줍니다. 이러한 시나리오에서 EmpathyEar는 각각 남성과 여성의 디지털 페르소나를 유연하게 맡아 정확하고 적절한 공감적 응답을 제공하며, 사용자의 감정을 긍정적으로 이끄는 역할을 효과적으로 수행합니다.

한계점 및 향후 연구 과제
(1) LLM과 텍스트 기반 명령으로 연결된 외부도구(백엔드 음성 생성기 및 말하는 얼굴 아바타 생성기)에 의존하고 있음 ⇒ 시스템에 엔드투엔드 학습이 부족함 ⇒ 계단식 오류 가능성: LLM 출력에서 발생한 오류가 다중 모달 생성으로 전파될 수 있습니다.
엔드투엔드(end-to-end)란? 시스템의 입력에서 출력까지 모든 과정이 하나의 통합된 모델이나 프로세스로 학습되고 처리되는 방식을 의미합니다. 즉, 중간 단계에서 별도의 모듈이나 외부 도구를 사용하지 않고, 전체 프로세스가 하나의 연속적인 학습 과정으로 이루어진다는 뜻입니다.
(2) 메타 응답(meta-response)이 가끔 일관성이 부족한 경우가 있음
의미적 및 감정적 표현에서 교차 모달(cross-modal) 일관성을 강화하는 방법을 탐구하는 것이 향후 연구의 초점이 될 수 있습니다.
교차모달 일관성을 강화한다는 것은?
여러 모달리티(Modalities) 간에 정보가 일관되게 표현되도록 만드는 것을 의미합니다. 여기서 "모달리티"란 데이터를 전달하는 서로 다른 방식(예: 텍스트, 음성, 이미지, 영상 등)을 뜻합니다.
즉, 교차 모달 일관성이란 텍스트, 음성, 이미지 등 서로 다른 모달리티 간에 의미와 감정 표현이 조화를 이루는 것을 말합니다.
ex) 이때, 텍스트로는 "축하해요!"라고 말하지만, 음성 톤이 슬프거나 얼굴 표정이 무표정이라면, 사용자에게 혼란을 줄 수 있습니다.
(3) 다중 모달 공감적 응답 생성에 대한 표준 정의 미흡 우리는 다중 모달 공감적 응답 생성이라는 개념을 도입했지만, 이 작업에 대한 포괄적인 벤치마크나 표준을 아직 정의하지 못했습니다. 미래 연구는 이 분야를 위한 명확한 정의, 데이터셋, 검증 방법을 수립하는 데 중점을 두어야 합니다.
'ai' 카테고리의 다른 글
| [기술면접] 트랜스포머란 무엇인가요? (0) | 2025.01.06 |
|---|---|
| [기술면접] 자연어 처리란 무엇인가요? (0) | 2025.01.05 |
| [진행중] 기술면접 질문 리스트 (1) | 2025.01.04 |
| 기술 검토의 중요성 (1) | 2024.11.09 |
| 인공지능의 역사 (3) | 2024.10.05 |
https://github.com/scofield7419/EmpathyEar
GitHub - scofield7419/EmpathyEar: Multimodal Empathetic Chatbot
Multimodal Empathetic Chatbot. Contribute to scofield7419/EmpathyEar development by creating an account on GitHub.
github.com
https://arxiv.org/abs/2406.15177
EmpathyEar: An Open-source Avatar Multimodal Empathetic Chatbot
This paper introduces EmpathyEar, a pioneering open-source, avatar-based multimodal empathetic chatbot, to fill the gap in traditional text-only empathetic response generation (ERG) systems. Leveraging the advancements of a large language model, combined w
arxiv.org
아키텍쳐 및 작업흐름 요약
EmpathyEar는 다중 모달 LLM입니다.
전체 시스템은 인코딩, 추론, 생성의 세 가지 블록으로 나눌 수 있습니다.
▶1단계: 사용자 질문 전달/API 호출
우리 시스템은 웹사이트 인터페이스 또는 사전에 정의된 API를 통해 사용자 입력을 수락합니다. 텍스트 입력, 음성(스피치) 입력, 또는 사용자가 말하는 영상 입력을 지원합니다.
▶2단계: 사용자 및 맥락(다중 모달) 입력 인코딩
사용자가 입력한 콘텐츠는 대화의 역사적 맥락과 함께 인코딩됩니다. 사용자의 입력이 텍스트만 포함된 경우, 그것은 직접 LLM(대형 언어 모델)으로 전달됩니다. 그러나 다중 모달 정보(음성 또는 영상)가 포함된 경우, 먼저 다중 모달 인코더를 거친 후 LLM으로 입력됩니다.
- 다중 모달 인코더(multimodal encoder)란?
- Text Embedding
- 사용자가 입력한 텍스트 데이터를 처리하고, 이를 모델이 이해할 수 있는 임베딩(embedding) 형태로 변환합니다.
- 텍스트 입력이 단독으로 주어졌을 경우, 바로 LLM으로 전달됩니다.
- Speech Encoder
- 사용자가 음성으로 입력한 데이터를 처리하여, 음성 신호에서 중요한 특징(예: 음성의 내용, 감정, 억양 등)을 추출합니다.
- 음성 데이터를 텍스트로 변환하거나, 음성 자체의 특성을 분석하여 LLM으로 전달합니다.
- Vision Encoder
- 사용자가 영상(예: 얼굴 표정, 제스처 등)을 입력한 경우, 이를 처리하여 영상에서 중요한 특징(예: 시각적 감정 표현, 얼굴 움직임 등)을 추출합니다.
- 이러한 시각적 정보를 LLM에 전달해 응답 생성에 반영합니다.
- Text Embedding
- 텍스트, 음성, 영상 등 다양한 입력 데이터를 처리하기 위한 모듈로 구성되며, 그림에서 언급된 Text Embedding, Speech Encoder, Vision Encoder가 각각 텍스트, 음성, 영상 입력을 처리하는 역할
- 다중 모달 특징을 동시에 인코딩하기 위해 사용된 것: ImageBind
- 우리는 이러한 다중 모달 특징을 동시에 인코딩하기 위해 ImageBind(Girdhar et al., 2023)를 활용하는 통합 접근 방식을 고려했습니다. ImageBind는 광범위한 **교차 모달 특징 정렬(cross-modal feature alignment)**을 거쳤으며, 다양한 모달리티 간 특징을 효율적으로 정렬할 수 있습니다. 그런 다음, **선형 투영층(linear projection layer)**을 통해 다중 모달 정보를 LLM으로 전달합니다.
- 파인튜닝1. 인코더 - LLM 정렬학습
- ‘오디오-텍스트’ 및 ‘비디오-텍스트’ 쌍에 대한 정렬학습을 수행합니다. 오디오와 비디오를 입력한 후, LLM이 해당하는 캡션을 출력하도록 설계합니다.
- ‘감정인식 기반 다중모달 정렬’을 수행하여 ImageBind & LLM이 음성과 비디오에서 감정특징을 인식하는 능력을 강화합니다. 이를 위해, 관련 데이터셋(예: EGG (Soleymani et al., 2015))을 사용하여 음성 기반(Sailunaz et al., 2018) 및 비전 기반(Jaiswal et al., 2020) 감정 인식 작업을 수행합니다.
- 시스템의 프론트엔드 모듈인 ImageBind를 LLM과 정렬하여, LLM이 다중 모달 정보를 이해할 수 있도록 합니다. 정렬은 두 가지 측면에서 고려됩니다
▶3단계: LLM을 사용한 메타 응답 생성
LLM은 입력된 콘텐츠를 완전히 이해하고, 이에 따라 결정합니다. 이 과정에서 감정 이해, 장면 이해, 사용자에게 반환될 텍스트 응답, 그리고 에이전트 프로필의 위치 설정을 포함한 메타 응답을 출력합니다.
- '메타 응답'이란?
- '메타 응답'이라는 용어는 단순한 텍스트 응답 이상의 정보를 포함하는, 시스템이 생성하는 고차원적인 응답을 의미 즉, 메타 응답은 단순히 사용자 질문에 대한 답변만 제공하는 것이 아니라, 시스템이 응답을 생성하기 위해 고려한 다양한 요소와 정보를 통합한 결과물을 말합니다.
- 사용된 백본(Backbone) LLM: Chat-GLM3
Chat-GLM3는 중국 기반의 Tsinghua University 와 Zhipu AI에서 개발한 모델로, 중국어와 영어를 포함한 다국어 환경에서 최적화된 GLM(General Language Model) 시리즈의 최신 버전입니다. 특히, 중국어 자연어 처리(NLP)에 강점을 가지고 있으며, 아시아 언어에 특화된 데이터셋으로 학습된 점이 특징입니다 - 다중 모달 입력을 받으면, LLM은 사용자의 **의미적 의도(semantic intentions)**와 **감정 상태(emotional state)**를 이해하여, 이후 콘텐츠 생성을 위한 모든 필수 정보를 포함한 **메타 응답(meta-response)**을 생성합니다.
- 이는 ChatGLM이 **Vicuna(Chiang et al., 2023)**나 **LLaMA(Touvron et al., 2023)**와 같은 다른 모델에 비해 뛰어난 텍스트 이해 및 대화 능력을 제공하기 때문입니다.
- 선형적으로 연결된 추론(linearly chained reasoning)우리는 LLM이 메타 응답의 네 가지 부분을 순차적으로 출력하도록 추가 프롬프트를 추가해 이를 안내합니다:
“1) 감정 → 2) 장면 맥락 → 3) 응답 내용 → 4) 에이전트 프로필을 단계별로 생각해 주세요.” - 파인튜닝2. 메타 응답 지침 튜닝
- 32가지 감정 레이블 유형(명시적 감정 유형과 암시적 감정 유형 모두 포함), 200개 이상의 실제 시나리오
- 우리는 OpenAI GPT-4(OpenAI, 2022a)를 활용하여 위에서 정의된 메타 응답 형식에 따라 풍부한 데이터를 생성합니다. 우리는 GPT-4가 CoT(Chain-of-Thought) 추론 형식을 완전히 준수하도록 프롬프트를 제공하여, LLM이 이 과정을 시뮬레이션하도록 합니다.
▶4단계: 참조 음성 검색
메타 응답에서 지정된 감정 레이블, 성별 및 음성 톤(timbre)을 기반으로 데이터베이스에서 참조 음성을 검색합니다.
▶5단계: 감정 인식 음성 생성
텍스트 응답과 참조 음성을 음성 생성기에 입력하여, 감정을 반영한 목표 음성을 생성합니다.
- 사용된 음성 생성기: StyleTTS2
- StyleTTS2는 주어진 텍스트, 감정 레이블, 그리고 참조 음성(예: 음색 및 성별 특성)을 기반으로 음성을 생성합니다.
▶ 6단계: 참조 얼굴 이미지 검색
메타 응답에서 결정된 프로필의 연령 및 성별 정보를 사용해 데이터베이스에서 참조 얼굴 이미지를 검색합니다.
▶ 7단계: 감정 인식 말하는 얼굴 아바타 영상 생성
생성된 감정을 반영한 음성과 참조 얼굴 이미지를 말하는 얼굴 생성기에 입력하여, 목표 감정을 반영한 말하는 얼굴 아바타 영상을 생성합니다.
- 사용된 얼굴 아바타 영상 생성기: EAT
- EAT는 주어진 음성, 감정 레이블, 그리고 디지털 인간의 얼굴 특징을 결정하는 참조 이미지를 조건으로 하여 해당 영상을 생성합니다.
- 디지털 아바타 캐릭터의 사전 설정 개요표 1: 우리 시스템에서 디지털 아바타 캐릭터의 사전 설정 개요
- 감정 레이블, 성별, 나이, 장면(scene), 음색(timbre) 및 톤(tone)을 포함
- 명시적(explicit) 및 암시적(implicit) 유형을 모두 아우르는 32가지의 일반적인 감정 레이블을 제공
- 인간의 나이는 신체적 외형 변화의 주요 단계를 기준으로 6단계
- 우리 시스템은 200개 이상의 실제 시나리오를 지원하며, 풍부한 음색과 톤을 가진 음성을 생성
- 파인튜닝3. 감정 인식 강화 학습
구체적으로, 음성 생성기와 얼굴 생성기를 각각 감정 음성 및 비디오 데이터셋인 **ESD (Zhou et al., 2022)**와 **MEAD (Wang et al., 2020)**에 대해 미세 조정(fine-tuning)합니다. 또한, ESD와 MEAD 데이터셋을 우리의 요구에 맞게 약간 수정합니다. - 예를 들어, 비디오 음성에서 텍스트를 인식한 후 이를 기반으로 음성 텍스트를 준비합니다.
- 백엔드 음성 생성기와 얼굴 생성기(talking-face generator)의 감정 인식 능력을 강화하기 위해, 기존의 관련 다중 모달 데이터를 활용하여 이 모듈들에 대해 추가 학습을 진행합니다.
▶8단계: 아바타 기반 다중 모달 공감 응답 반환
시스템은 이번 턴의 전체 출력 콘텐츠로 텍스트 응답, 음성, 말하는 얼굴 아바타 영상을 요약하여 사용자에게 반환합니다.
- 비디오 데모: https://youtu.be/gGn9oYftwbY
그림 3과 4에서는 두 가지 시나리오(노인 동반자 및 심리 상담)에서 시스템이 사용자와 상호작용하는 모습을 보여줍니다. 이러한 시나리오에서 EmpathyEar는 각각 남성과 여성의 디지털 페르소나를 유연하게 맡아 정확하고 적절한 공감적 응답을 제공하며, 사용자의 감정을 긍정적으로 이끄는 역할을 효과적으로 수행합니다.
한계점 및 향후 연구 과제
(1) LLM과 텍스트 기반 명령으로 연결된 외부도구(백엔드 음성 생성기 및 말하는 얼굴 아바타 생성기)에 의존하고 있음 ⇒ 시스템에 엔드투엔드 학습이 부족함 ⇒ 계단식 오류 가능성: LLM 출력에서 발생한 오류가 다중 모달 생성으로 전파될 수 있습니다.
엔드투엔드(end-to-end)란? 시스템의 입력에서 출력까지 모든 과정이 하나의 통합된 모델이나 프로세스로 학습되고 처리되는 방식을 의미합니다. 즉, 중간 단계에서 별도의 모듈이나 외부 도구를 사용하지 않고, 전체 프로세스가 하나의 연속적인 학습 과정으로 이루어진다는 뜻입니다.
(2) 메타 응답(meta-response)이 가끔 일관성이 부족한 경우가 있음
의미적 및 감정적 표현에서 교차 모달(cross-modal) 일관성을 강화하는 방법을 탐구하는 것이 향후 연구의 초점이 될 수 있습니다.
교차모달 일관성을 강화한다는 것은?
여러 모달리티(Modalities) 간에 정보가 일관되게 표현되도록 만드는 것을 의미합니다. 여기서 "모달리티"란 데이터를 전달하는 서로 다른 방식(예: 텍스트, 음성, 이미지, 영상 등)을 뜻합니다.
즉, 교차 모달 일관성이란 텍스트, 음성, 이미지 등 서로 다른 모달리티 간에 의미와 감정 표현이 조화를 이루는 것을 말합니다.
ex) 이때, 텍스트로는 "축하해요!"라고 말하지만, 음성 톤이 슬프거나 얼굴 표정이 무표정이라면, 사용자에게 혼란을 줄 수 있습니다.
(3) 다중 모달 공감적 응답 생성에 대한 표준 정의 미흡 우리는 다중 모달 공감적 응답 생성이라는 개념을 도입했지만, 이 작업에 대한 포괄적인 벤치마크나 표준을 아직 정의하지 못했습니다. 미래 연구는 이 분야를 위한 명확한 정의, 데이터셋, 검증 방법을 수립하는 데 중점을 두어야 합니다.
'ai' 카테고리의 다른 글
| [기술면접] 트랜스포머란 무엇인가요? (0) | 2025.01.06 |
|---|---|
| [기술면접] 자연어 처리란 무엇인가요? (0) | 2025.01.05 |
| [진행중] 기술면접 질문 리스트 (1) | 2025.01.04 |
| 기술 검토의 중요성 (1) | 2024.11.09 |
| 인공지능의 역사 (3) | 2024.10.05 |