
멀티턴 대화 학습과정에서 가장 먼저 해야 할 일은 '데이터셋 준비'이다.
aihub와 같은 데이터셋 제공 플랫폼에서 멀티턴 대화 데이터를 제공하지만,
이 데이터를 어떤 형태로 가공해서 학습시키는 것이 최적일지에 대해서는 정답이 없다.
왜냐하면, 이는 모델 구조(gpt,bert,rnn 등), 학습목표(생성, 분류, 요약), 도메인(오픈 도메인 vs 태스크 지향형) 에 따라 달라질 수 있기 때문이다.
그래서 이 포스팅에서는 다양한 후보의 대화 데이터셋 형태를 제시해보고자 한다.
예를 들어, 대화를 단순히 역할별로 나열할지, 전체 대화를 하나의 시퀀스로 처리할 지에 따라 결과가 달라질 수 있다.
참고로, 우리 프로젝트는 라마 3 모델을 사용해서, 사용자의 입력에 맞는 메세지를 생성할 수 있는 것을 목표로 하고,
일상대화를 하나의 도메인으로 보고, 친구관계에서 할 수 있는 인간적인 대화를 태스크(태스크 지향형)로 보고 있다.
일상대화를 하나의 도메인으로 볼 수 있는 이유?
- 도메인: 특정 주체나 맥락에서 이루어지는 대화의 범위를 의미합니다.
- 일상대화의 특징: 일상대화의 주제 자체가 하나의 광범위한 도메인으로 간주될 수 있습니다.
예를 들어, 일상대화의 주제로는 건강 및 식음료, 문화 생활 및 여가, 경제 및 사회, 콘텐츠 소비 등이 있습니다.
친구관계에서 할 수 있는 인간적인 대화를 태스크로 볼 수 있는 이유?
- 태스크 지향형 대화 : 특정한 목표를 달성하기 위해 설계된 대화를 의미한다. 예를 들어, 여행 예약, 음식주문 등이 대표적인 예이다.
- 친구관계 대화의 특징
- "친구관계에서 할 수 있는 인간적인 대화"는 단순히 일상대화의 범주에 머무르지 않고, 특정한 목적을 지향한다고 볼 수 있습니다.
- 예를 들어,
- 감정적 지원 : "오늘 기분이 어때?" → "힘들었겠다. 내가 도와줄게."
- 친밀감 형성: "요즘 무슨 영화 봤어?" → "그 영화 나도 보고 싶었어!"
- 조언 제공: "내일 중요한 발표가 있어." → "잘할 수 있을 거야. 준비는 어떻게 하고 있어?
- 이러한 대화는 단순히 정보 교환이나 자유로운 주제의 대화가 아니라, 친구 관계를 유지하고 강화하려는 명확한 목적을 가지고 있습니다.
- 태스크로 정의할 수 있는 이유
- 친구관계에서의 대화는 단순한 "오픈 도메인" 대화가 아니라, 특정한 상호작용 방식(친밀감, 공감, 조언)을 요구합니다.
- 이는 AI모델이 단순히 정보를 생성하는 것 이상으로, 친구처럼 대화하는 방식을 학습해야 함을 의미합니다.
후보 1. 역할 기반 멀티턴 데이터
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant, but not too helpful."
}, {
"role": "user",
"content": "Can you give me some advice on starting a new project?"
}, {
"role": "assistant",
"content": "Of course, I'd be happy to help. What's the project about?"
, {
"role": "user",
"content": "It's a mobile app for language learning."
}, {
"role": "assistant",
"content": "That sounds interesting! What specific features are you planning to include in the app?"
}
}
]
},
위에서 제시된 JSON 구조는 역할 기반 멀티턴 데이터의 대표적인 예입니다.
이 데이터는 GPT 모델과 같은 대화형 AI모델에서 사용하기 위해 설계된 형식으로, '역할(role)' 과 '여러 턴(turn)'의 대화흐름을 포함하고 있습니다.
대화의 역할을 구분하여, 모델이 각 역할에 따라 적절히 응답하도록 돕습니다:
- system: AI의 초기 설정을 정의. 여기서는 "너무 도움을 주지는 않는 어시스턴트"로 설정.
- user: 사용자의 요청이나 질문.
- assistant: AI 모델의 응답.
데이터셋의 길이는 실제 대화에서 기대되는 턴 수와 유사하게 구성해야 한다는 점이 강조됩니다.
후보 2. Collapsed context 방식
Collapsed context 방식은 대화형 모델에서 이전 대화의 일부(혹은 전체)를 요약하거나 제거하여 모델에게 전달하는 방식입니다. 이는 대화 히스토리를 압축하거나 제한된 토큰 길이 내에서 효율적으로 관리하기 위해 사용됩니다.
예를 들어
- 사용자가 이전에 했던 여러 발화를 요약하거나 생략하고, 마지막 발화만 모델에게 전달.
- 이전 대화의 핵심 정보를 추출하여 모델이 사용하는 prompt에 포함.
Collapsed Context 방식의 부정적 의견
(1) 대화의 연속성 손실
대화형 AI 모델은 사용자의 맥락과 의도를 이해하기 위해 이전 발화를 참조해야 합니다.
만약 이전 대화의 중요한 부분이 생략되거나 요약되면, 모델은 사용자의 의도를 완전히 이해하지 못할 수 있습니다.
=> 특히 멀티턴 대화(multi-turn conversation)에서는 대화의 흐름이 끊길 위험이 있습니다.
(2) Fine-tuning 데이터셋 설계의 문제
OpenAI의 fine-tuning 가이드라인 중 일부는 멀티턴 대화를 포함한 데이터셋을 권장합니다. 이는 대화형 애플리케이션이 자연스러운 대화를 유지하기 위해 중요합니다.
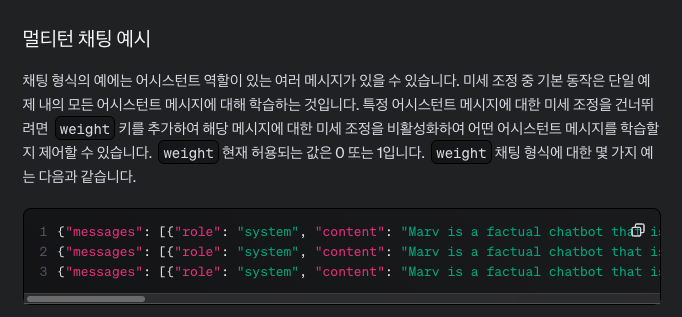
만약 collapsed context 방식을 고수하면, fine-tuning 데이터셋이 단일 턴(single-turn) 예제로만 구성될 가능성이 높아지고, 이는 다중 턴 대화를 요구하는 애플리케이션에서 비효율적일 수 있습니다.
참고
https://community.openai.com/t/openai-fine-tuning-multi-turn-dataset-examples/465039
OpenAI Fine-Tuning: Multi-turn Dataset Examples
I’m new to OpenAI model fine-tuning. I am fine-tuning gpt3.5-turbo for a conversational chatbot. This is part of a series of questions I’ve quickly collected as I’m learning this alchemy. A question about mutli-turn training data. TL;DR: Yes to multi
community.openai.com
https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset#preparing-your-dataset
'ai' 카테고리의 다른 글
| [기술면접] 본인 프로젝트에서 어떤 파인튜닝 기법을 사용하셨나요? (0) | 2025.01.23 |
|---|---|
| [기술면접] 맡은 파트와 한 일이 뭐죠? (0) | 2025.01.08 |
| [기술면접] 인공신경망이란 무엇이고, 어떻게 작동되나요? (0) | 2025.01.08 |
| [기술면접] 딥러닝과 머신러닝의 차이점? (1) | 2025.01.08 |
| [Together.ai] 멀티턴 대화 파인튜닝 하는법 (0) | 2025.01.07 |
멀티턴 대화 학습과정에서 가장 먼저 해야 할 일은 '데이터셋 준비'이다.
aihub와 같은 데이터셋 제공 플랫폼에서 멀티턴 대화 데이터를 제공하지만,
이 데이터를 어떤 형태로 가공해서 학습시키는 것이 최적일지에 대해서는 정답이 없다.
왜냐하면, 이는 모델 구조(gpt,bert,rnn 등), 학습목표(생성, 분류, 요약), 도메인(오픈 도메인 vs 태스크 지향형) 에 따라 달라질 수 있기 때문이다.
그래서 이 포스팅에서는 다양한 후보의 대화 데이터셋 형태를 제시해보고자 한다.
예를 들어, 대화를 단순히 역할별로 나열할지, 전체 대화를 하나의 시퀀스로 처리할 지에 따라 결과가 달라질 수 있다.
참고로, 우리 프로젝트는 라마 3 모델을 사용해서, 사용자의 입력에 맞는 메세지를 생성할 수 있는 것을 목표로 하고,
일상대화를 하나의 도메인으로 보고, 친구관계에서 할 수 있는 인간적인 대화를 태스크(태스크 지향형)로 보고 있다.
일상대화를 하나의 도메인으로 볼 수 있는 이유?
- 도메인: 특정 주체나 맥락에서 이루어지는 대화의 범위를 의미합니다.
- 일상대화의 특징: 일상대화의 주제 자체가 하나의 광범위한 도메인으로 간주될 수 있습니다.
예를 들어, 일상대화의 주제로는 건강 및 식음료, 문화 생활 및 여가, 경제 및 사회, 콘텐츠 소비 등이 있습니다.
친구관계에서 할 수 있는 인간적인 대화를 태스크로 볼 수 있는 이유?
- 태스크 지향형 대화 : 특정한 목표를 달성하기 위해 설계된 대화를 의미한다. 예를 들어, 여행 예약, 음식주문 등이 대표적인 예이다.
- 친구관계 대화의 특징
- "친구관계에서 할 수 있는 인간적인 대화"는 단순히 일상대화의 범주에 머무르지 않고, 특정한 목적을 지향한다고 볼 수 있습니다.
- 예를 들어,
- 감정적 지원 : "오늘 기분이 어때?" → "힘들었겠다. 내가 도와줄게."
- 친밀감 형성: "요즘 무슨 영화 봤어?" → "그 영화 나도 보고 싶었어!"
- 조언 제공: "내일 중요한 발표가 있어." → "잘할 수 있을 거야. 준비는 어떻게 하고 있어?
- 이러한 대화는 단순히 정보 교환이나 자유로운 주제의 대화가 아니라, 친구 관계를 유지하고 강화하려는 명확한 목적을 가지고 있습니다.
- 태스크로 정의할 수 있는 이유
- 친구관계에서의 대화는 단순한 "오픈 도메인" 대화가 아니라, 특정한 상호작용 방식(친밀감, 공감, 조언)을 요구합니다.
- 이는 AI모델이 단순히 정보를 생성하는 것 이상으로, 친구처럼 대화하는 방식을 학습해야 함을 의미합니다.
후보 1. 역할 기반 멀티턴 데이터
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant, but not too helpful."
}, {
"role": "user",
"content": "Can you give me some advice on starting a new project?"
}, {
"role": "assistant",
"content": "Of course, I'd be happy to help. What's the project about?"
, {
"role": "user",
"content": "It's a mobile app for language learning."
}, {
"role": "assistant",
"content": "That sounds interesting! What specific features are you planning to include in the app?"
}
}
]
},
위에서 제시된 JSON 구조는 역할 기반 멀티턴 데이터의 대표적인 예입니다.
이 데이터는 GPT 모델과 같은 대화형 AI모델에서 사용하기 위해 설계된 형식으로, '역할(role)' 과 '여러 턴(turn)'의 대화흐름을 포함하고 있습니다.
대화의 역할을 구분하여, 모델이 각 역할에 따라 적절히 응답하도록 돕습니다:
- system: AI의 초기 설정을 정의. 여기서는 "너무 도움을 주지는 않는 어시스턴트"로 설정.
- user: 사용자의 요청이나 질문.
- assistant: AI 모델의 응답.
데이터셋의 길이는 실제 대화에서 기대되는 턴 수와 유사하게 구성해야 한다는 점이 강조됩니다.
후보 2. Collapsed context 방식
Collapsed context 방식은 대화형 모델에서 이전 대화의 일부(혹은 전체)를 요약하거나 제거하여 모델에게 전달하는 방식입니다. 이는 대화 히스토리를 압축하거나 제한된 토큰 길이 내에서 효율적으로 관리하기 위해 사용됩니다.
예를 들어
- 사용자가 이전에 했던 여러 발화를 요약하거나 생략하고, 마지막 발화만 모델에게 전달.
- 이전 대화의 핵심 정보를 추출하여 모델이 사용하는 prompt에 포함.
Collapsed Context 방식의 부정적 의견
(1) 대화의 연속성 손실
대화형 AI 모델은 사용자의 맥락과 의도를 이해하기 위해 이전 발화를 참조해야 합니다.
만약 이전 대화의 중요한 부분이 생략되거나 요약되면, 모델은 사용자의 의도를 완전히 이해하지 못할 수 있습니다.
=> 특히 멀티턴 대화(multi-turn conversation)에서는 대화의 흐름이 끊길 위험이 있습니다.
(2) Fine-tuning 데이터셋 설계의 문제
OpenAI의 fine-tuning 가이드라인 중 일부는 멀티턴 대화를 포함한 데이터셋을 권장합니다. 이는 대화형 애플리케이션이 자연스러운 대화를 유지하기 위해 중요합니다.
만약 collapsed context 방식을 고수하면, fine-tuning 데이터셋이 단일 턴(single-turn) 예제로만 구성될 가능성이 높아지고, 이는 다중 턴 대화를 요구하는 애플리케이션에서 비효율적일 수 있습니다.
참고
https://community.openai.com/t/openai-fine-tuning-multi-turn-dataset-examples/465039
OpenAI Fine-Tuning: Multi-turn Dataset Examples
I’m new to OpenAI model fine-tuning. I am fine-tuning gpt3.5-turbo for a conversational chatbot. This is part of a series of questions I’ve quickly collected as I’m learning this alchemy. A question about mutli-turn training data. TL;DR: Yes to multi
community.openai.com
https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset#preparing-your-dataset
'ai' 카테고리의 다른 글
| [기술면접] 본인 프로젝트에서 어떤 파인튜닝 기법을 사용하셨나요? (0) | 2025.01.23 |
|---|---|
| [기술면접] 맡은 파트와 한 일이 뭐죠? (0) | 2025.01.08 |
| [기술면접] 인공신경망이란 무엇이고, 어떻게 작동되나요? (0) | 2025.01.08 |
| [기술면접] 딥러닝과 머신러닝의 차이점? (1) | 2025.01.08 |
| [Together.ai] 멀티턴 대화 파인튜닝 하는법 (0) | 2025.01.07 |